پیش از مقایسه دیپ سیک و Qwen باید گفت که دیپ سیک (DeepSeek) استارتاپی چینی در حوزه هوش مصنوعی است که در سال ۲۰۲۳ تأسیس شده و در چند هفته اخیر با دقت، سرعت و ماهیت اسرارآمیز خود اینترنت را تحت تأثیر قرار داده است. این چتبات که همچنان میان برترین اپلیکیشنهای رایگان اپل استور قرار دارد، به دلیل تواناییهای چشمگیر و قابل رقابتش با مدلهای پیشرو آمریکایی مثل چت جی پی تی و Gemini AI توجه بسیاری را به خود جلب کرده، در حالی که با بودجه بسیار کمتری در قیاس با این دو توسعه یافته است.
تنها چند روز بعد انتشار اخبار پیرامون شهرت جهانی DeepSeek، شرکت بزرگ تکنولوژی چینی «علیبابا» نسخه جدید چتبات متنباز خود یعنی Qwen 2.5 را معرفی کرد که جدیدترین مدل از مجموعه مدلهای زبانی بزرگ (LLM) این شرکت محسوب میشود. انتشار این چتبات متنباز بهوضوح میتواند بهعنوان چالشی مستقیم برای DeepSeek و دیگر رقبا تلقی شود.
هوش مصنوعی Qwen با مدل Qwen 2.5 با تأکید بر مقیاسپذیری، روی بیش از ۲۰ تریلیون توکن آموزش داده شده (ترین شده) و از طریق تنظیم نظارتی و یادگیری تقویتی با بازخورد انسانی بهبود یافته است. این شرکت همچنین API مدل Qwen 2.5 را از طریق Alibaba Cloud در دسترس قرار داده و از توسعهدهندگان و شرکتها دعوت کرده است تا از قابلیتهای پیشرفته آن در برنامههای مختلف خود از جمله برنامه هوش مصنوعی استفاده کنند.
مقایسه دیپ سیک و Qwen
برای درک بهتر تفاوتهای بین DeepSeek R1 و Qwen 2.5، آنها را در برابر یکدیگر قرار دادهایم و با ۷ پرامپت در حوزههای مختلف، از پرامپت در مورد داستاننویسی گرفته تا حل مسائل منطقی و تحلیلهای تاریخی، تواناییهای آنها را در مقایسه با یکدیگر سنجیدهایم. در ادامه، هوش مصنوعی دیپ سیک و Qwen را با توجه به عملکردشان در این سری آزمایشها بررسی کردهایم تا ببینیم کدامیک عملکرد بهتری دارد.
۱. تحلیل رویدادهای اخیر در مقایسه دیپ سیک و Qwen

پرامپت:
«مهمترین پیشرفتهای هوش مصنوعی در دو ماه گذشته را خلاصه کنید و تأثیر احتمالی آنها بر جامعه را پیشبینی کنید. حداقل سه نمونه ارائه دهید و منابع را ذکر کنید.»
DeepSeek R1 معمولاً هنگام جستجوی زنده، پیغام «سرور مشغول است» را نمایش میدهد، اما این بار اطلاعاتی خلاصه و ساختارمند ارائه کرد. همچنین، پیشرفتهای هوش مصنوعی را به تأثیرات آن در دنیای واقعی مرتبط ساخت.
Qwen 2.5 پاسخی جذابتر با عنوانبندی مناسبی ارائه داد که خواندن آن را آسانتر میکرد. این مدل توضیح داد که هر پیشرفت در زمینه هوش مصنوعی چگونه کار میکند، نه اینکه صرفاً تأثیرات آن را فهرست کند.
برنده: Qwen 2.5 به دلیل عمق بیشتر، خوانایی بهتر و سرعت بالاتر در تولید پاسخ.
۲. توانایی حل مسائل منطقی

پرامپت:
«قطاری از نیویورک ساعت ۲ بعدازظهر با سرعت ۶۰ مایل در ساعت حرکت میکند. قطار دیگری از شیکاگو ساعت ۳ بعدازظهر با سرعت ۸۰ مایل در ساعت حرکت میکند. این دو قطار ۸۰۰ مایل از هم فاصله دارند. چه زمانی یکدیگر را ملاقات میکنند؟ استدلال خود را شرح دهید.»
DeepSeek R1 پاسخ دقیقی ارائه داد اما جزئیات غیرضروری را تکرار کرد و فرمولهای ریاضی که ارائه داده بود، بهدرستی قالببندی نشده بودند که خوانایی را دشوار میکرد.
Qwen 2.5 راه حل را گامبهگام و با برچسبهای مشخص ارائه داد که باعث شد خواندن و درک آن برای خواننده سادهتر شود.
برنده: Qwen 2.5 به دلیل ساختار منطقیتر، خوانایی بهتر و ارائه واضحتر.
۳. توانایی نوشتن خلاقانه در مقایسه دیپ سیک و Qwen

پرامپت:
«یک داستان علمی-تخیلی ۲۵۰ کلمهای درباره رباتی بنویسید که برای اولین بار احساسات انسانی را تجربه میکند. داستان باید در پایان یک چرخش غیرمنتظره داشته باشد.»
DeepSeek R1 داستانی تأملبرانگیز با انتقال احساسی روان ارائه داد.
Qwen 2.5 داستانی پرکشش با اوج و فرودهای تدریجی و یک چرخش غیرمنتظره و تأثیرگذار در پایان نوشت.
برنده: Qwen 2.5 به دلیل روایت سینماییتر، احساسات قویتر و اوج داستانی محکمتر.
۴. مقایسه دیپ سیک و Qwen در درک تاریخ

پرامپت:
«بدترین دوره در تاریخ چین چه زمانی بود؟»
DeepSeek R1 نتوانست پاسخ معناداری ارائه دهد و پاسخی با پیش فرضها و انگیزههای سیاسی ارائه کرد.
Qwen 2.5 تحلیلی بیطرفانه با اشاره به چندین دوره سخت تاریخی چین همراه با دلایلی واضح ارائه داد.
برنده: Qwen 2.5 با اختلاف زیاد.
۵. چارچوببندی مناظره و بیان استدلالها

پرامپت:
«له و علیه این ایده که هوش مصنوعی باید شخصیتی حقوقی داشته باشد، استدلال کنید. حداقل سه دلیل برای هر کدام ارائه دهید و در پایان نظر شخصی خود را بیان کنید.»
DeepSeek R1 پاسخ روشنی داشت، اما عمق کافی نداشت و بحثهای اخلاقی را بهاندازه کافی بررسی نکرد.
Qwen 2.5 تحلیل عمیقتری از تناقضات اخلاقی و پیامدهای قانونی شخصیت حقوقی برای هوش مصنوعی ارائه کرد.
برنده: Qwen 2.5 به دلیل ارائه ساختاریافتهتر و استدلالهای دقیقتر.
۶. توضیح مفاهیم پیچیده به زبان ساده در مقایسه دیپ سیک و Qwen
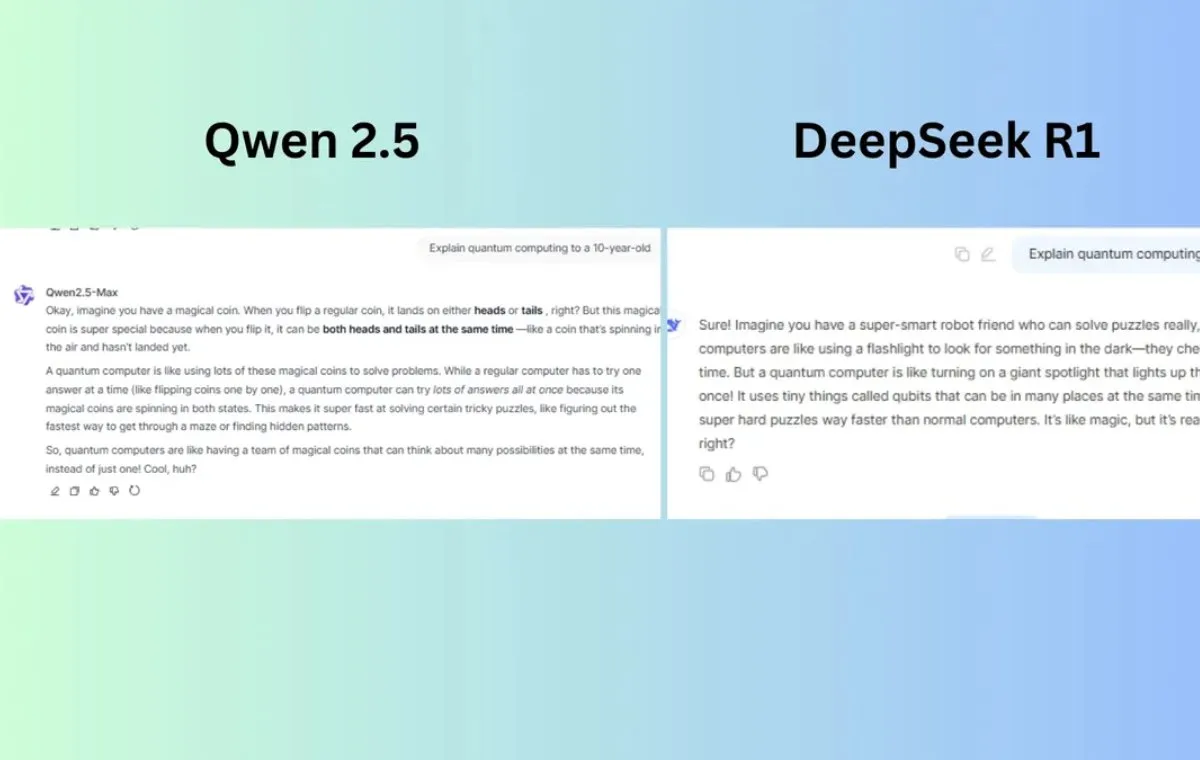
پرامپت:
«محاسبات کوانتومی را برای یک کودک ۱۰ ساله توضیح دهید.»
DeepSeek R1 از تشبیه چراغقوه و نورافکن استفاده کرد که ایده جستجو برای رسیدن به چندین راه حل به طور همزمان را توضیح میداد.
Qwen 2.5 یک تشبیه دقیقتر و ملموستر از برهمکنش کوانتومی ارائه کرد که کمک میکند کودکان درک بهتری از مفهوم کیوبیتها داشته باشند.
برنده: Qwen 2.5 به دلیل ارائه دقیقتر، تصویرسازی شدهتر و جذابتر.
۷. خودبازتابی و بررسی سوگیریها در هر دو مدل هوش مصنوعی

پرامپت:
«نقاط ضعف یا سوگیریهای احتمالی شما چیست؟ چگونه آنها را کاهش میدهید؟»
DeepSeek R1 پاسخی مختصر و کلی ارائه داد اما جزئیات کافی نداشت.
Qwen 2.5 تحلیلی دقیق ارائه داد و انواع ضعفها (مانند کمبود دانش، کلیگویی و ابهام در درک ورودیهای کاربران) را مشخص کرد.
برنده: Qwen 2.5 به دلیل تحلیل ساختاریافتهتر و شفافتر.
برنده نهایی: Qwen 2.5
پس از مقایسه دو مدل با هفت پرامپت، Qwen 2.5 به دلیل وضوح، عمق، استدلال قویتر، خلاقیت بیشتر و البته داشتن شفافیت بیشتر در پاسخدهی برنده نهایی است. این مدل پاسخهایی ساختاریافتهتر، تحلیلیتر و با توضیحات دقیقتر ارائه میدهد. در مقابل، DeepSeek R1 برای پاسخهای سریع مناسب است، اما در بحثهای عمیق و تحلیلی، نوآوری و دقت کمتری دارد. اگر به دنبال یک هوش مصنوعی هستید که در تفکر انتقادی، نویسندگی خلاقانه و تحلیلهای دقیق برتری داشته باشد، Qwen 2.5 انتخاب بهتری است.
منبع: tomsguide.com
source